前言
最近在写织梦的验证码识别遇到的小问题,用pytesseract默认的字典效果不是很理想于是就有了这篇文章。 记录一下方便查询
介绍
谷歌的开源框架 tesseract-ocr可以帮助我们进行识别图像,文字等等,tesseract可以识别多种语言(一些常用的语言),多种图片格式,非常强大。
相关工具
下载并安装tesseract(配置环境变量,后面需要用到)
地址:https://sourceforge.net/projects/tesseract-ocr/
下载并安装jTessBoxEditor(用于纠正)
地址:http://vietocr.sourceforge.net/training.html
集合
https://github.com/tesseract-ocr/tesseract/wiki/AddOns
准备工作
1、准备要识别的典型图片用作测试图片,将图片转为tif格式的(在线转换地址,还可以用自带的画图打开,选择另存为tif)
2、用jTessBoxEditor把所有的测试图片合成一张 (打开jTessBoxEditor.jar,然后点菜单上的Tool->Merge TIFF)
生成识别字典
1、在合成的tif文件夹打开cmd进入 why4.tif 所在的目录,生成对应的 .box 文件输入以下命令(why为合成的tif)
tesseract why.tif why4 batch.nochop makebox
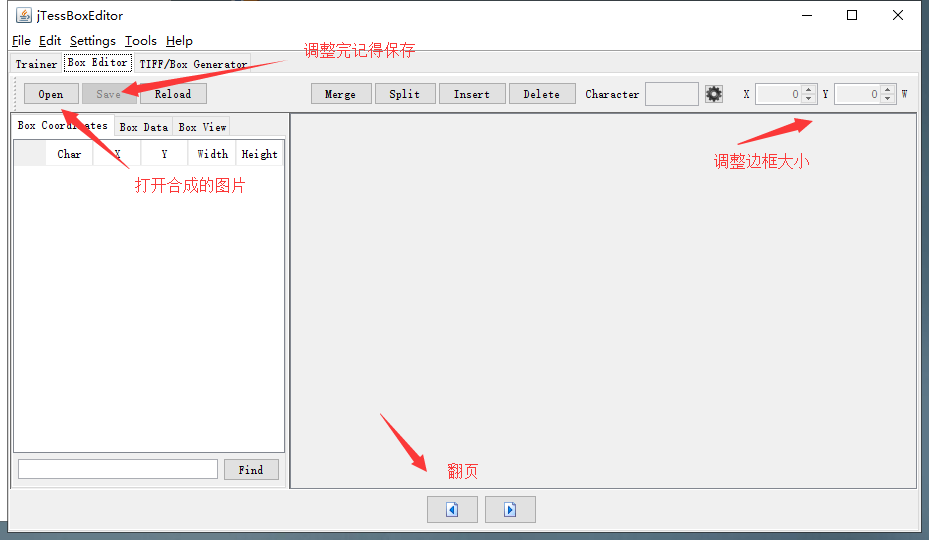
2、用 jTessBoxEditor来调整识别文字的位置、结果。
用 jTessBoxEditor打开生成的图片集why4.tif ,注意 why4.tif 对应的box文件一定要和他处于同一个文件夹下(请保持文件名),否则,用jTessBoxEditor打开没有 位置、识别结果等信息,然后就可以调整了,调整完之后保存
 3、生成.tr文件
3、生成.tr文件
tesseract why4.tif why4 nobatch box.train
4、计算字符集,从生成的 box文件中提取
unicharset_extractor why4.box
5、生成字体特征文件,现在文件夹下新建文件名为“"font_properties.txt"” 特征文件内容为:
why4 0 0 0 0 0
6、输入命令
mftraining -F font_properties.txt -U unicharset why4.tr
7、聚集tesseract 识别的训练文件
cntraining why4.tr
执行完这一步之后发现文件夹下生产了许多文件,把unicharset, inttemp, normproto, pffmtable, shapetable这几个文件加上前缀 why4.
8、最后一步,合并相关文件,生成字典文件
combine_tessdata why4.
9、好了,至此字典文件就生产了,我们把生成的字典文件why4.traineddata放入到 tesseract_ocr 根目录下的 tessdata文件夹下
10、修改识别语言包
code = pytesseract.image_to_string(img,lang='why')
参考
https://blog.csdn.net/zhanghaiming012/article/details/80522992 https://www.jianshu.com/p/6633a7a85add
